

Value isn’t directly proportionate to accuracy
It’s quick to build AI-powered automations that are partially accurate. Partially may even stretch to pretty good, like 90%, just by plugging GPT into a workflow. You can easily upload a PDF invoice and ask ChatGPT to extract key information like names, values and dates into a spreadsheet. This looks impressive, and you can even vibe code a product out of it.
You then find the vibe-coded solution delivers no value when deployed to real users. Errors are often costly, and you don’t know where the 10% of errors are. Is a database with errors in 10% of its data valuable? If not, the user has to check 100% of the AI’s output, even if it’s 90% accurate. This may not save any time compared to just reading the invoice themselves, so they end up ditching the automation.
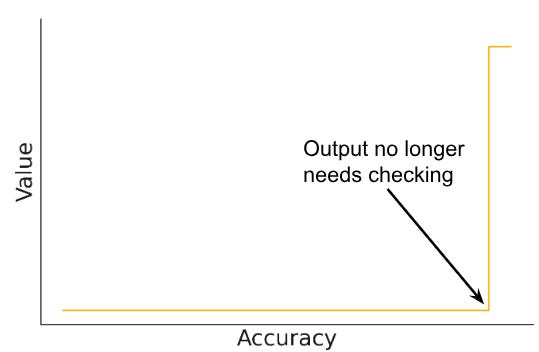
It’s very common for 90% (or higher) accuracy to deliver zero value in practice. That’s because value is non-linear: at some point, you cross a threshold where the user no longer has to check the output, and it saves a ton of time. Low-accuracy initial deployments are fine to get started, but you then need to find some way to bring accuracy above this threshold. Two key questions for getting real value from AI are:
Can you tolerate errors? If you’re replacing a human process, the answer must be yes to some extent, as humans make mistakes.
If so, how often? This is not a technical question. The market decides, so you can only find out by deploying a product to market.
Success stories
Tasks where the human baseline is low are likely to make good candidates for AI. Google has long used AI to rank results in order of relevance. The existing alternative was ranking in some other form e.g. recency. It wasn’t hard for AI to beat this low baseline and provide something much more useful..
In some tasks, you can slice the data to separate the portion that’s error-prone from the highly accurate portion. For example: passport scanners are accurate provided the passport photo is good quality and the person is in clear view of the camera. The AI can let most people through without any need for human review. In only a minority of cases, they’re sent to border guards for review. This saves tons of time.
Tasks where mistakes are very tolerable are also easier to automate. A good example is AI to generate online content for SEO ranking. Writing this content took a long time, and no one was reading it very carefully, so clearly mistakes were tolerable. The accuracy threshold for bringing an AI Blog Writer to market was very low.
Lastly, there are some tasks where reviewing the output is far faster than creating it from scratch, such as creating concept art. Drawing images takes a long time, but AI can do this very quickly. It can also do a lot of them, so it’s easy for a human to generate new concepts until they find one they like. It’s very quick to review the “mistakes” and fix them by generating more images or post-editing.
Caution: converting unstructured to structured data
Converting unstructured data to structured data is a very common use case. For example: an accountant may receive invoices in PDF form, which are unstructured. They extract structured data, such as values and tax rates, into an accounting database like QuickBooks or Xero. It’s easy to imagine an AI doing this and saving them a ton of time.
Are errors tolerable? Yes. Auditors often find that bookkeepers make mistakes, and the accounts are revised afterwards. You get a chance to correct your mistakes.
How often are errors tolerable? Suppose the AI is 90% accurate e.g. for every 10 data points it extracts from an invoice, 9 are correct. This likely isn’t enough - a human makes fewer mistakes. If the bookkeeper needs to check every line of data against the original invoice, this won’t save time compared to just extracting the data manually.
To make the 90% AI useful, we’d likely need to redesign the workflow around it. For example: we could speed up the human check with a splitscreen showing a PDF on the left, with extracted info highlighted, and the output on the right. This requires product thinking too - we can’t just naively plug the AI into an existing workflow.
Caution: the “AI personal assistant”
There are lots of startups building AI personal assistants. It can take phone calls, read emails and schedule meetings for you. The idea’s very appealing: it will automate all your busywork!
Can you tolerate errors? Maybe not. What if it books a meeting at the wrong time, or sends an email to the wrong person? It’s pretty hard to see how 90% accuracy, or even 99%, would be good enough in this case - the 1% of emails that are sent to the wrong person could have dire consequences.
You could get around this by checking every appointment the AI books for you, or reviewing every email it drafts. But this wouldn’t save you any time compared to just doing the work yourself. You’re probably not going to be able to correct its mistakes.
The market decides what’s good enough, not us AI engineers. But do you know anyone paying for an AI personal assistant yet?
Caution: Self-driving cars
Self-driving cars provide a cautionary tale. They’ve outperformed human drivers for a long time, at least in cities, in terms of safety and reliability. Yet they’re still far from widespread deployment, it feels like they’ve been “2 years away” for decades. It’s still unclear what the “good enough” threshold is for self-driving car accuracy.
Mistakes are hard to tolerate because the consequences are often severe. And the decisions need to be taken in real-time, so there are no second chances. You can’t revise a driving decision in the way you can revise your company’s accounts. AI applications whose results have real-time impacts are going to be harder to deploy.
Find the threshold, you must
Your AI might make mistakes very rarely. But if those mistakes are costly, you’ll have to check its output 100% of the time. This usually adds no value in practice, so you want to avoid AI deployments that go down this route.
The key to success is finding the threshold at which you no longer need to check the AI’s output. This isn’t easy. A sensible starting point is to measure human performance on a task, which will never be 100%. If your AI can reach human performance, there’s a chance it’ll be good enough for successful deployment.
However, for some tasks human performance is far from good enough (see: self-driving cars). To help figure out the threshold, ask the following questions:
How much can you tolerate mistakes? If a human was previously doing the task, there must be some error tolerance as humans make mistakes. But some mistakes are worse than others.
Does the AI’s output have real-time consequences? If so, you may not get a chance to revise it when mistakes happen.
Getting value from software that isn’t 100% reliable is hard, but this is the key to more widespread deployment of AI in real-world tasks. When it works, the payoff is huge, so it’s worth putting the effort into doing it properly!
For more help with AI reliability, you can find us at https://www.artanis.ai/
Something interesting to think about: how does accountability affect accuracy threshold? People often feel more comfortable with humans making mistakes that they can blame on them, than AI making mistakes where blame is fuzzy. I think that's the big barrier to self-driving cars (or any other automation where the consequences involve loss of life, e.g. autonomous drones targeting humans; cf "Kill Decision" by Daniel Suarez)