


Intro - the last mile is a lack of trust
We’re getting closer to a world where anyone can build their own AI products. It’s now pretty easy for most people to prompt ChatGPT into doing a wide range of tasks for them - no coding background needed.
Unfortunately, there’s a last-mile problem. People don’t feel in control of the outputs of their AI. Without control, they lack trust. As a result, people are reluctant to deploy anything beside human-in-the-loop use cases. Without full automation, AI's impact on the real economy will be limited.
Fortunately, we’ve found the solution to the last mile, which we call Policy. Policy is now all that’s needed to bring about a world where anyone can build their own AI products and trust them.
Who are we to tackle the last mile?
We finished our PhDs back in 2021, which now feels like a long time ago. Our most recent research, on how to evaluate LLM accuracy, was published in the first Conference on Language Models. It has since been used by teams at Google & Nvidia, and we even got a call from the Director of AI at the White House!
In May 2024, we turned our flood of inbound AI consulting leads into Artanis. Artanis began as an agency helping companies build AI products. They got in touch with us for many reasons, but it always boiled down to their AI not doing what they wanted. They didn’t feel they could trust it, so couldn’t deploy it effectively in the market. We knew how to fix their AI problems and bootstrapped to £50k MRR by December.
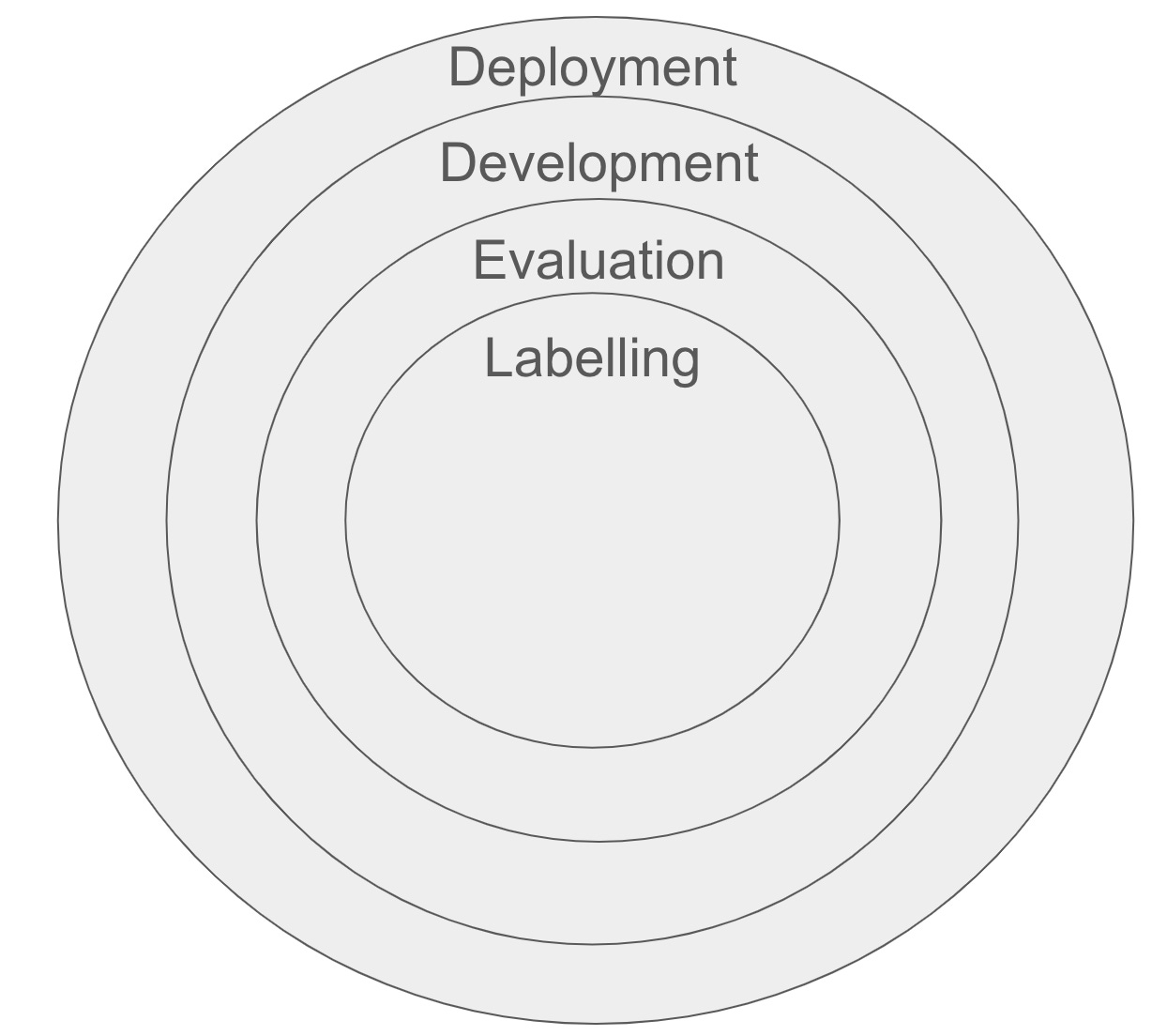
We built a repeatable system for delivering trustworthy AI projects. To deploy a model, you first need to iterate on it to the point where you trust its output (“development”). But to iterate, you need to be able to evaluate how accurately it’s performing (“evaluation”). To evaluate, you need a consistent dataset of instructions for the model (“labelling”).
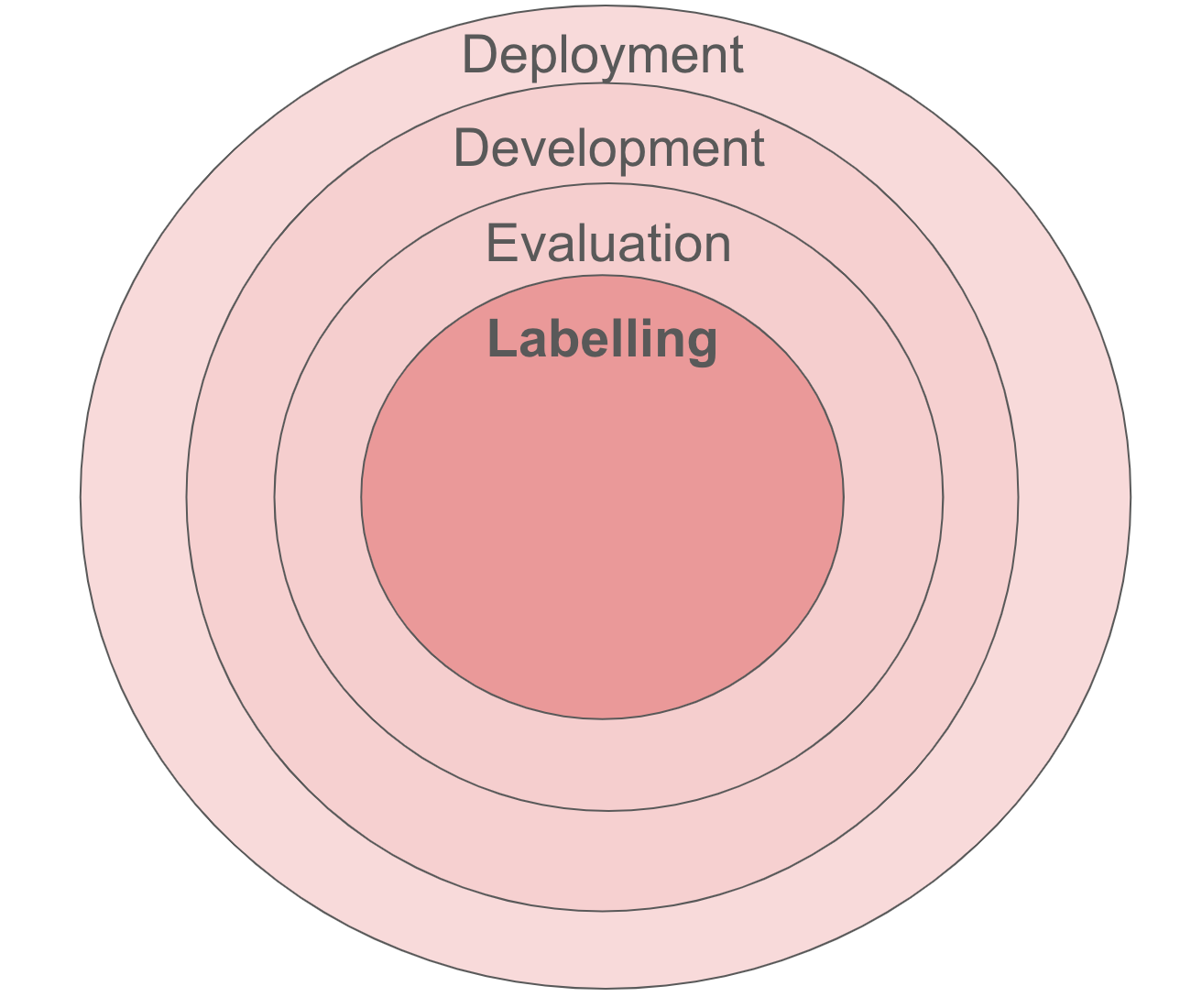
We found a rot at the core of our system. We initially thought we were being brought in to fix the outer layers by setting up evaluation, development and deployment. But none of them were labelling their data consistently. And without well-labelled data, we couldn’t evaluate. Without evaluation, we couldn’t iterate on AI to make it accurate enough to trust. And you can’t deploy AI that you don’t trust. Unless you just need to make a demo video - many investors pay top dollar for those!
Why is labelling so hard now?
Labelling is instructing your AI what you want it to do by giving a large number of specific instructions. This started with machine learning tasks like image recognition. Is this image a cat or a mouse? Is it a hot dog or not a hot dog? The correct label, or “ground truth”, is unambiguous so the AI has a consistent pattern to learn. These tasks could easily be outsourced at a low cost.
The labelling game has changed a lot recently. With modern AI problems, ground truth is the eye of the beholder. AI labelling tasks now look more like this:
“You’re an English teacher marking children’s essays for spelling. Give them a pass if they spell consistently across a wide range of vocabulary”.
Consistently is not defined. Is it zero mistakes, 1, 5, 20% of words?
Wide range of vocabulary is not defined. Adverbs? Adjectives? Nouns? How many of each?!
Following these instructions, two people could label a given essay completely differently. If they have different mental definitions of the ambiguous terms, one person could give it a pass and the other could give it a fail. There is no consistent pattern to learn, which is catastrophic for AI evaluation.
No wonder AI models aren’t doing what people expect them to. Without consistently-labelled data, the instructions we give them are ambiguous.
Policy: the missing core of the AI stack
Artanis solves the last mile by enabling users to instruct their AI without ambiguity.
We call this purging of ambiguity their “Policy”.
“You’re an English teacher marking children’s essays for spelling. Give them a pass if they spell consistently across a wide range of vocabulary
Consistently means they make zero mistakes.
Wide range of vocabulary means they use at least one noun, adjective and adverb.”
Artanis is not just about teaching the AI how the human thinks - it helps humans understand how AI “thinks”. 0s and 1s. Right and wrong. Artanis teaches people to embrace black-and-white thinking. We are making the human labeller closer to an AI.
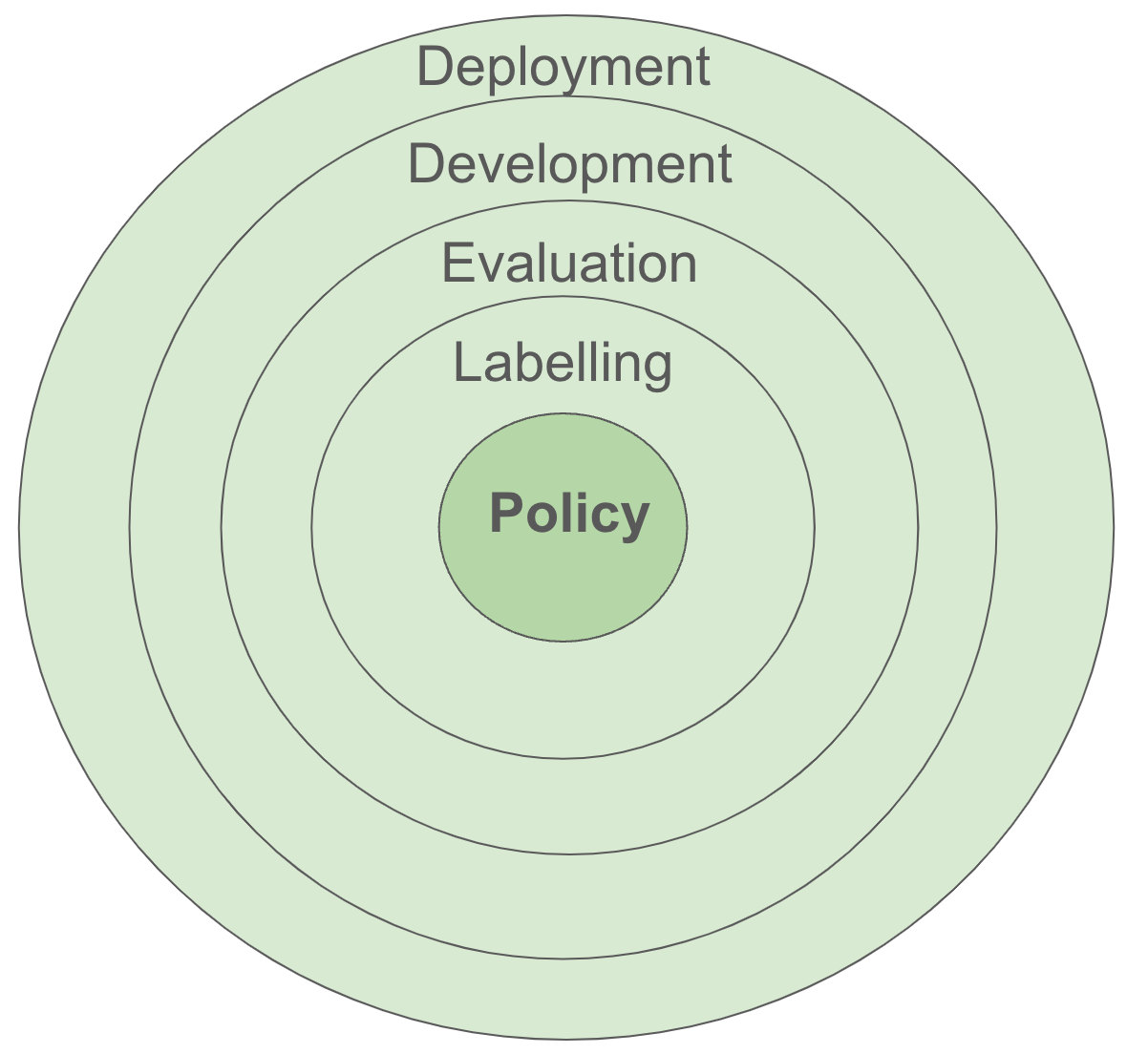
Policy is the missing core of the AI stack. With a well-defined policy, users can label their data consistently. The rest of the stack now rests on solid foundations.
Well labelled-data solves the last mile
With a solid foundation of well-labelled data, everything else falls into place. Given well-labelled data, evaluation is a simple piece of software - it’s super crowded. Given solid evaluation, development is AutoML or automated prompt engineering. An LLM agent can take care of it as the agent has a target to iterate toward. Deployment has been commoditised for a very long time.
To cross the last mile, we need to enable people to define their policy and label data consistently. With that, we can finally give anyone the means to build and deploy AI all by themselves. Even better, it will be AI they can trust to do a job reliably. And that’s the Artanis vision!
En Taro Tassadar
Came back to this in relation to: https://www.microsoft.com/en-us/research/uploads/prod/2025/01/lee_2025_ai_critical_thinking_survey.pdf
Seems Policy is an example of the way "GenAI shifts the nature of critical thinking toward information verification, response integration, and task stewardship."