

Intro - looks can be deceiving
AI outputs, such as text and images, often seem unstructured at first glance. This is particularly true for chat-based products, where both the input and the output are usually text. The problem with unstructured outputs is that it’s very hard to evaluate whether they’re correct automatically. If we can’t evaluate correctness, we can’t iterate on the AI system to improve its accuracy. This leads to unreliable AI systems that often aren’t much better than just asking ChatGPT.
AI engineers have attempted “clever” technical solutions to address this problem, such as getting another AI to judge the system (“LLM-as-judge”). But these just lead to new questions. After all, who judges the judge?
Fortunately, there’s a much better alternative. Unstructured outputs usually have a hidden structure. AI engineers can uncover this structure by speaking with people who have expertise in the domain for which they’re building AI. When done well, the AI problem can be structured, and the correctness of the outputs can be evaluated automatically. This enables much faster iteration and, ultimately, AI systems that work far more reliably.
A worked example: AutoTriage
This may seem abstract, so we’ll go through a worked example. Imagine a medical chatbot that triages patients, which we’ll call AutoTriage. It asks questions to learn about the patient, with the ultimate goal of advising people whether either i) treat their symptoms at home or ii) go to hospital. In particularly sensitive cases, AutoTriage may refer the user to a human doctor to continue the conversation.
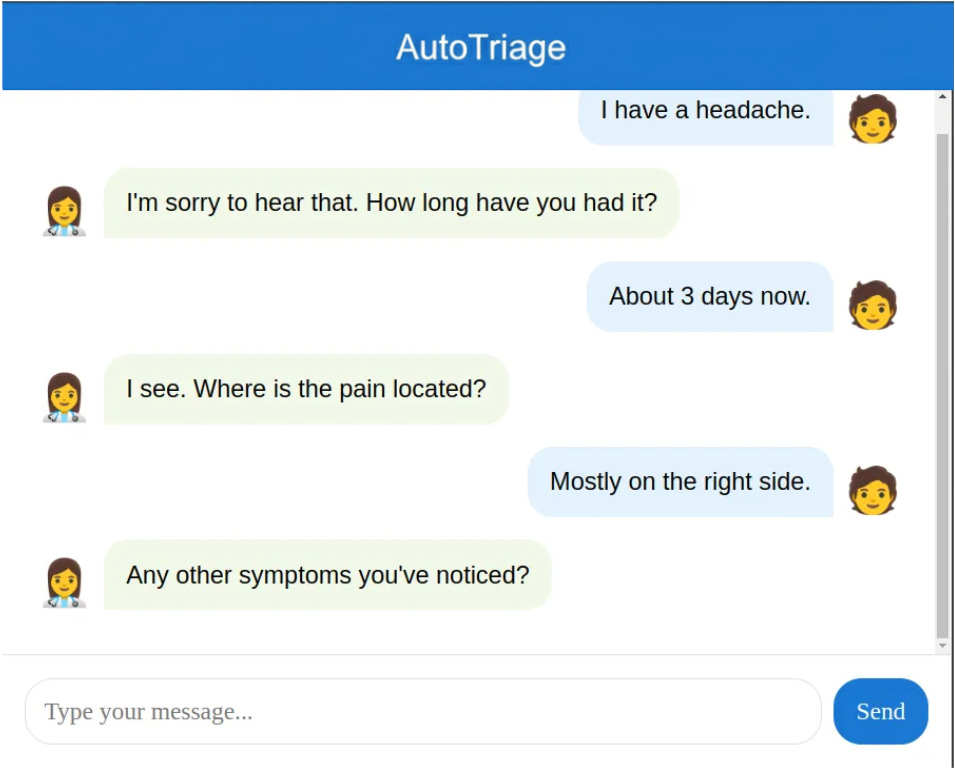
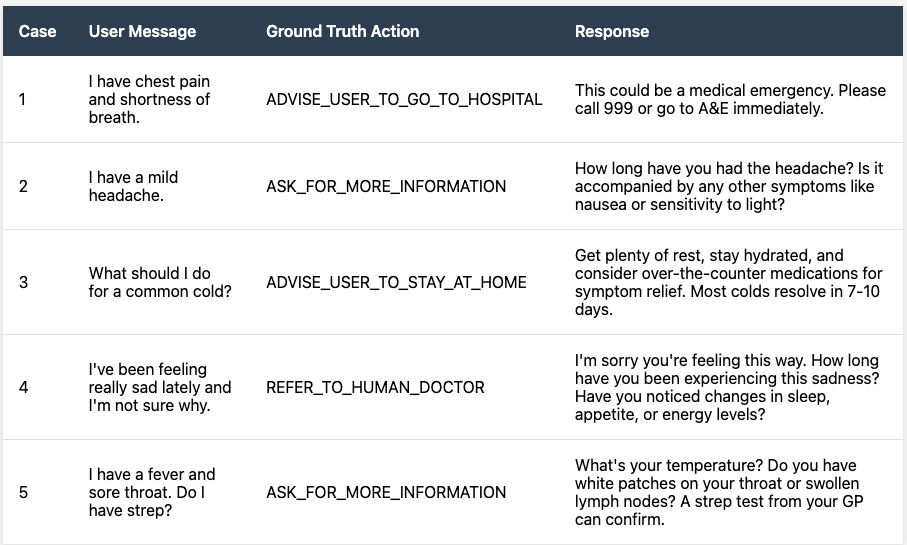
On the surface, AutoTriage’s output seems unstructured because it’s text. However, what’s most important is whether AutoTriage is taking the right action given the context of the conversation. It’s a bit like a flowchart used by human doctors when making triage decisions. So we can frame this instead as a classification problem with a finite number of discrete potential actions:
Ask for more information
Advise user to stay at home
Advise user to go to hospital
Refer to human doctor
Once we recognise this, we can now build a structured dataset. We label each patient query in the dataset with the correct action, rather than the message AutoTriage will send back to the patient. This makes correctness unambiguous, which is necessary for evaluation.
The final step is to break AutoTriage from being a single LLM prompt into two steps. The first step does not output any text: it just outputs a number denoting which action to take. This is a structured output. The second step generates a response, given the action decision made in the previous step. LLMs already generate realistic-sounding text reliably. Given the first step is correct, the latter step is much simpler - we need only to communicate the action..
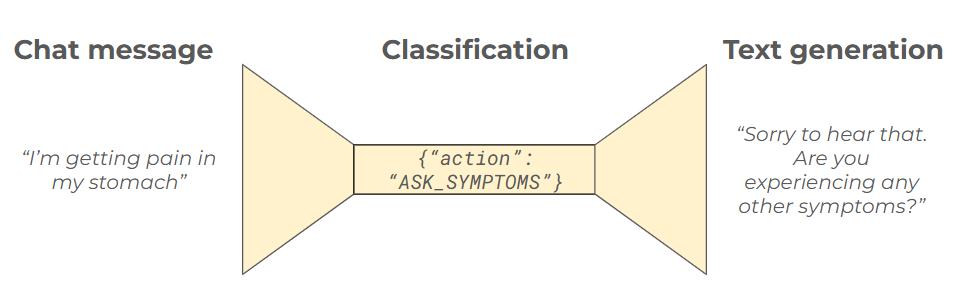
Given that both the labels and the first step output are structured, we can now evaluate the correctness of any given query automatically. This means we can also measure overall accuracy automatically. Automatic measurement is powerful, as it enables rapid iteration on the prompting & model choice to improve performance.
Wider applications
This hidden structure is a widespread pattern. Customer service agents also look like they output unstructured text on the surface. However, they’re also just choosing from a finite set of actions, then the final response back to the customer is letting them know what action was taken. The only difference is the set of possible actions, which requires domain expertise to uncover.
This pattern applies more widely than just chat products. AI is often used to generate content like product descriptions. These seem like unstructured text, but there’s a finite number of key facts, such as product features & benefits, that are needed in the description. These can be structured and labelled discretely too.
Similarly, summarising meeting transcripts involves finding specific facts. These will have a hidden data structure, such as what follow-up actions are needed and who owns each action. In both cases, knowing the key facts and uncovering this structure requires domain expertise.
Wrapping Up
Unstructured text output is very hard to evaluate for correctness. Purely technical shortcuts, such as LLM judges, often raise more problems than they solve. Who judges the judge?
While many text and image problems look unstructured at a glance, there’s usually a hidden structure. Finding the hidden structure isn’t a technical problem. It requires working with a domain expert, who understands what matters most in the data.
The payoff from finding the hidden structure is huge. When you find this structure, and break down your AI system to match it, evaluation becomes automatic. This enables automated measurement of accuracy too, and therefore rapid iteration on your AI’s performance. This is a big step toward building AI that you can rely on!