

This is the first in a series about building AI that works in the real world:
Breaking down a problem into steps (this post)
Unfortunately, this won’t be as concise as “5 sick use cases of ChatGPT!!!” or “Did OpenAI just kill 10,000 startups with their latest release?!” If you want that, you can go elsewhere. But if you’re willing to read longer content, and want to build AI that actually works, please read on!
Intro - are you saying AI doesn’t work?
Rates of AI project failure have always been high, and ChatGPT has made this worse. Much worse. For the first time, people who can’t code think they can build reliable AI. This confidence is horribly misplaced, given that 99% of those who can code still can’t build AI that works reliably.
To tackle real-world problems, AI engineers need a blend of statistics, coding, and curiosity about real-world (not just computer) systems. Very few people have this skill set - they’re quickly sucked up by a few big labs like Google, Meta, Microsoft, OpenAI and Amazon. Even big tech struggles: during our PhDs, we never heard a top AI researcher say “I’m applying for Apple''.
AI problems always boil down to data problems. An AI engineer must understand the real-world (not computer) system that generates their data. This means speaking to the real people who create the data and understanding their thought processes. Unfortunately, most AI engineers don’t want to do this.
A common-but-wrong approach: the one-shot black box
Let’s get concrete with an example from a past project. A startup was building an AI to generate floor plans for architecture. Users put in a list of rooms, then the AI would generate a realistic floor plan. Sounds pretty dope!
There was just one problem: the generated floor plans weren’t realistic. After 12 months of work, they still often came out with smudges, curved lines and other random noise. After speaking with their AI engineers, we learned they were training a one-shot image generation model. The list of rooms would go in and an image out, with no intermediate steps.
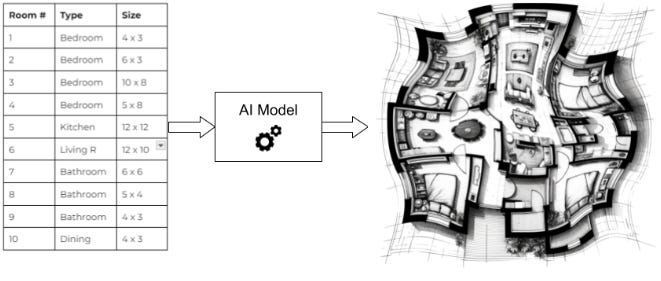
While their approach makes sense at a glance, precise image generation is impossible. Their images were 100 * 100 pixels, so the problem required getting ~10,000 pixels. Even if the model was 99.9% accurate on a pixel basis: the chance of getting all 10,000 pixels correct would be 0.999 10,000 = 0.004%. This may be fine when users don’t know precisely what they want e.g. making concept art. However, floor plans need precision - they shouldn’t have any blurred lines.
The rare-but-right approach: start by talking to people
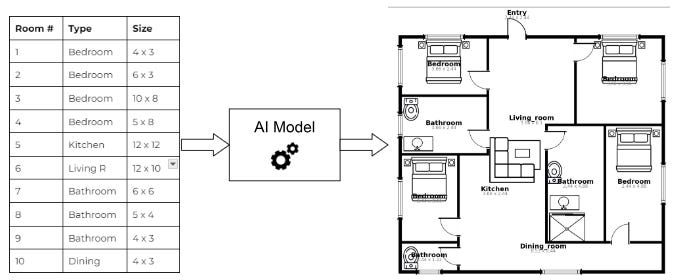
We first spoke to an architect about how they draw floor plans. It turns out they don’t go straight from a list of rooms to the image at the end: there is an intermediate step, where they first decide which rooms go next to each other. This isn’t an image at all, it’s a matrix with 1s when rooms are next to each other and 0s when they aren’t. Once they have the matrix, they just draw rectangles on top to show the rooms.
For a list of 10 rooms, the size of this matrix is 10 x 10. Getting 100 elements right is much easier than 10,000 for an AI model. We advised their AI engineers to get rid of the image generator entirely, instead breaking the problem into two parts:
Train an AI to map the list of rooms to a small adjacency matrix
Use a regular non-AI function to draw rectangles on top of the matrix.
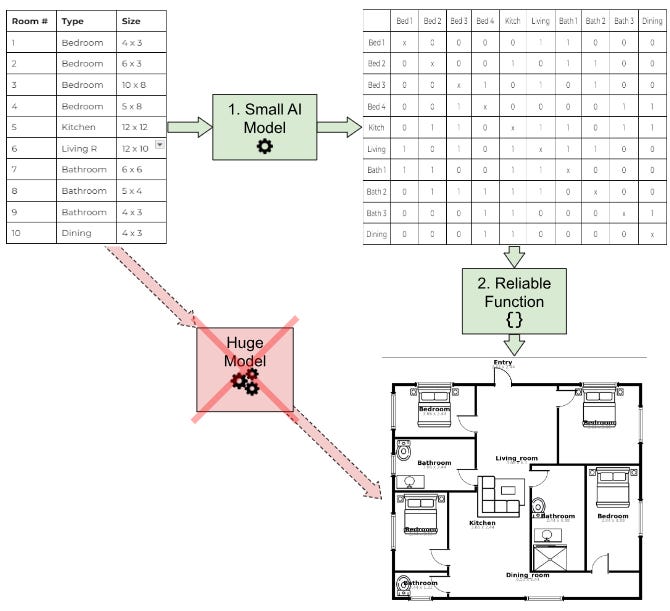
These images never had smudges because the rectangle-drawing function is reliable and deterministic. With just two Zoom calls, we’d made more progress than their previous year of training the one-step AI to generate images. The key insight was to remove AI where it wasn’t needed.
“AI engineers” often make this mistake when they have basic data science training, but no interest in the real-world process that generates the data. They believe that if they feed enough data into their model, it will eventually do what they want. In theory, they’re right. However, the amount of data they’d need is usually several orders of magnitude more than they have.
Conclusion - how to break down AI problems correctly
You must first learn about the real-world process that generates the data. This means speaking to the people involved in “labelling” the data i.e. determining what correct looks like. We can only break a problem down into a step-by-step system once we understand their thinking. To instruct a machine, you must first write a playbook that a human could follow.
Once you break the problem down into steps, you decide which steps use AI. You use AI as little as possible - most steps are implemented with reliable functions. AI is a last resort, only used when writing a reliable function isn’t feasible. In a best-case scenario, you don’t need to use AI for any step, and the overall system is 100% reliable!
Once the problem has been broken down this way, the size of any remaining AI step will be much smaller. Smaller problems are much easier for an AI to solve reliably. Avoiding AI also cuts the risk of steps passing unreliable outputs to each other, and errors compounding through the system.
Many people reading this won’t be AI engineers themselves. Instead, you may be hiring them or working with them as colleagues. If you’re wondering why your AI engineer is failing, ask the following questions:
Do they understand the real-world (not computer) system that generates the data? They should be speaking to people who are close to the data.
Once they understand the real-world process, do they break the high-level problem into smaller steps?
Finally, and most importantly, do they treat AI as a last resort? Where possible, they write reliable functions instead of AI.
If your engineers aren’t ticking these boxes, they probably don’t have the right skill set. We’re not arguing that anyone is to blame - it’s just that building AI that actually works is hard!
I came here for "Did OpenAI just kill 10,000 startups with their latest release?!"