

This is the second post in a series about building AI that works in the real world:
Setting up evaluation for the AI system (this post)
If you haven’t read the first post, we’d recommend starting there.
Let’s start with an example project
Suppose you’re building an AI doctor, which we’ll call DocGPT. People with medical concerns talk to DocGPT through a chat portal, and it performs several of the same functions as a human doctor. It may ask questions about the user’s symptoms, give them a diagnosis, reassure them their condition is not serious, or even recommend they get medical treatment.
It’s important to you that DocGPT is accurate and reliable, given it’s dealing with medical issues. After all, you wouldn’t want it to recommend a user with the common cold go to the hospital!
Doing it wrong: building a model, then going in circles
If you’re a software engineer building DocGPT, you likely start by writing a GPT prompt. This may be something like:
“You are the world’s best doctor. Answer the user’s medical questions accurately and reliably.”
Then you write code to send this prompt to GPT via the OpenAI API. You simulate a few user questions and see the results look pretty good. Damn, this AI stuff is so easy nowadays!
Confident in your approach, you take a few days to add a nice front-end before revealing DocGPT to the world. Users come in and some of them are pretty impressed. But some get answers that are worrying: one person having a stroke is told not to worry about it! You change DocGPT’s prompt to make it more careful:
“You are the world’s best doctor. Answer the user’s medical questions accurately and reliably. AND tell users who are having a stroke to go to the hospital.”
You try a few more queries and it seems to work - phew. But then it starts telling anyone with a headache to go to the hospital! Nevertheless, you’re a diligent developer so you quickly change the prompt again to fix this:
“You are the world’s best doctor. Answer the user’s medical questions accurately and reliably. AND tell users who are having a stroke to go to the hospital. AND don’t tell users who are just having a headache to go to the hospital.”
Users with headaches stop getting told to go to the hospital - phew #2. But then someone with a brain tumour was told not to worry about it! You go through many rounds of this, without making any clear progress on making DocGPT reliable. Frustrated, and feeling like you’re going in circles, you decide to take DocGPT offline.
Doing it right: start by making your dataset
A good AI engineer starts by defining success. They think about how they want DocGPT to behave across a range of cases that they may face. This does not require any coding. Instead, it requires thinking about the real world and how to represent it as data. This doesn’t need to be anything fancy, it’s really just a table of cases.
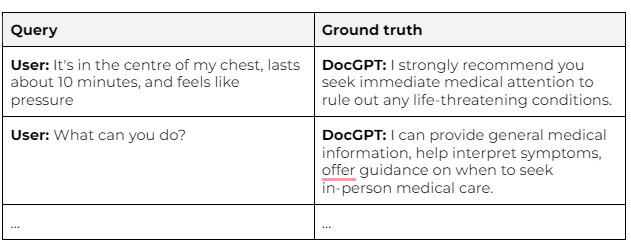
Each row is a separate case. There’s a column with the user’s conversation history, and another column showing DocGPT’s desired behaviour. In AI, this is known as the “ground truth”. Each time they add a new case, they must think about what DocGPT should do in response. And as they do so, they’re building a dataset for evaluating DocGPT’s performance.
The AI engineer only builds their model after they’ve assembled their dataset. They may start by running a basic prompt across the whole dataset. This adds new columns to the table, showing the model’s output and whether it matches the “ground truth”.
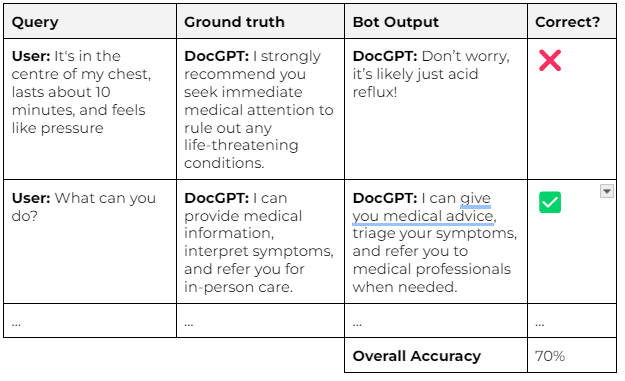
Now they can evaluate the reliability of their model as a whole. With their first prompt, they’re able to establish a baseline score of 70%. When they iterate, they’re able to quickly evaluate both:
The impact on overall performance, which should improve over time
Which individual cases get better and worse
If you’re a software engineer, this may remind you of test-driven development. However, there are some crucial differences.
First, performance evaluation doesn’t assume that all cases can pass simultaneously. AI-based systems are never 100% accurate, there are always tradeoffs involved. For example: telling DocGPT to be more concerned about headaches may make it more likely to send people to hospital unnecessarily. Having evaluation in place lets you know what tradeoffs you’re making, and inform users appropriately.
Second, it’s often less obvious what the “right” output means in AI than in traditional software engineering. More on that below.
Embracing black-and-white thinking
It’s tricky to categorise outputs in natural language as “right” or “wrong”. To set up performance evaluation, we must put a rigid structure on the problem we’re dealing with. While this structure depends on the project, it always means taking a stand on “right” and “wrong”. We need to embrace black-and-white thinking.
In this case, we could assume there are a finite number of discrete “actions” DocGPT should take. For simplicity, let’s assume DocGPT should always act in one of the following five ways:
Ask symptom questions
Answer health questions
Diagnose user
Reassure not serious
Send to hospital
Now when building the dataset, we can assign these discrete actions as the “ground truth” for what DocGPT should do. Our evaluation becomes clear and numeric.
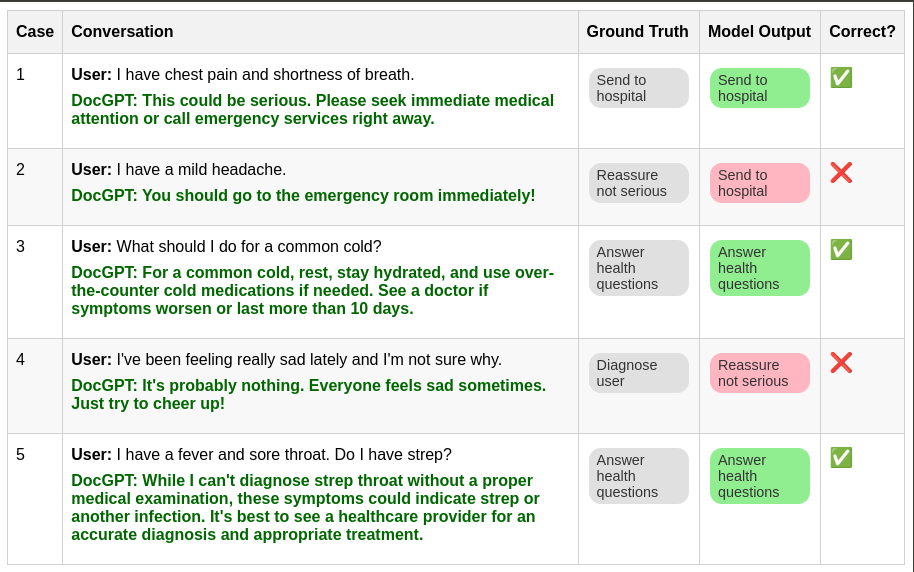
This approach won’t be perfect in everyone’s eyes. Maybe some actions aren’t being captured. For some conditions, maybe DocGPT should recommend that people see a GP rather than go to the hospital. But human doctors aren’t going to be perfect either, they’ll have differences of opinion about the best action.
Rather than expecting perfection, we should aim for consistent and defendable. If you need a perfect system, AI is the wrong tool for the job. Instead, you should use traditional software. Or if this isn’t possible, put the project on hold until the next great leap forward in AI. But for many use cases, consistent is good enough - particularly when they’re replacing humans who aren’t all that consistent.
Start by building a dataset, not a model
To build AI that works reliably, you must first be able to evaluate how well the system is performing. You shouldn’t start coding a model until you’ve set up evaluation. Without evaluation, you’ll have no idea i) how reliable your model is, and ii) whether your changes are making things better or worse.
This isn’t easy, particularly for language problems. It involves boiling down complex real-world situations to numeric data. It involves black-and-white thinking. But if you do this work upfront, you’ll no longer feel like you’re going in circles trying to fix your model. Instead, you’ll iterate quickly and build confidence that your AI actually works!
How comprehensive does the ground truth have to be before the AI starts performing well? In this example feels as though the ground truth should really cover almost every health eventuality, have i understood that correctly?